
W3C Trace Context
The W3C Trace Context specification is a set of new standards developed by open source and commercial tool providers that defines a unified approach to the context and event correlation within distributed systems, such as microservices environments. Such a standard will enable end-to-end transaction tracing within distributed applications across various monitoring tools.
To fully understand the value that a unified context propagation specification can provide, you should first understand the concepts of distributed tracing, context propagation, and the related challenges.
Why we need distributed tracing
Distributed tracing is used to understand the control flow within distributed systems (i.e., how transactions flow through multiple distributed services). While distributed tracing has been around for over a decade, it’s gained renewed interest recently with the rise of microservices architectures. While it may still be possible to track the execution flow of transactions within traditional “monolithic application” environments, this is certainly not the case when working with numerous microservices, where control flows can become highly dynamic (for example, with service meshes or circuit breakers that change the execution flow of transactions at runtime).
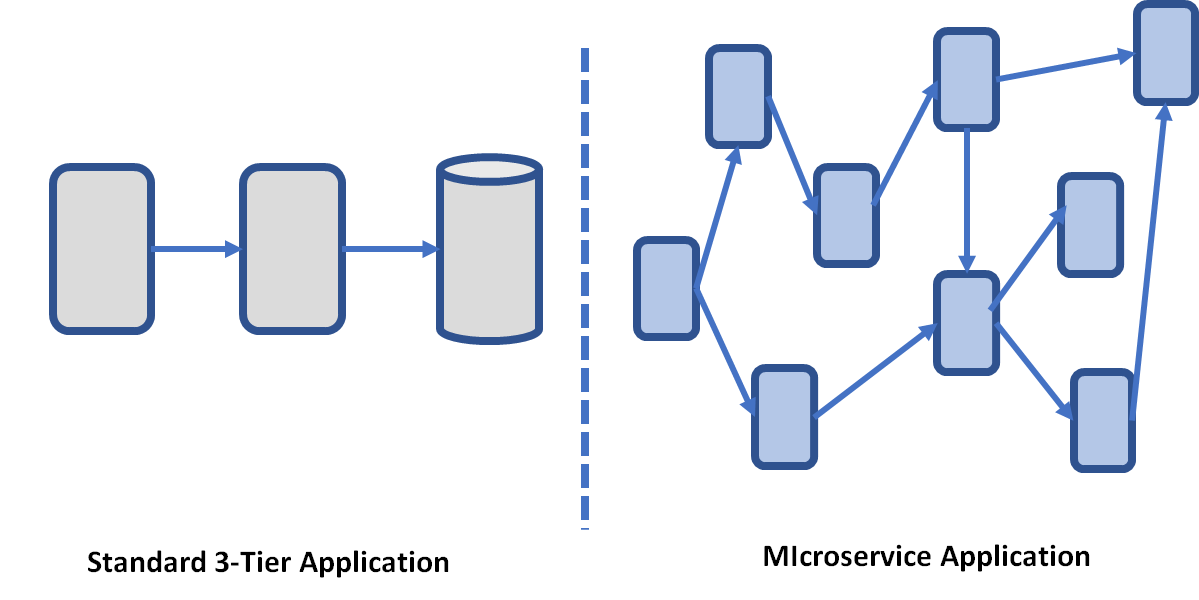
Microservice applications are significantly more complex than traditional 3- tier apps
Context propagation: The core building block of distributed tracing
To make distributed tracing work, we need a way to pass context information from one transaction to the next. Such a transaction context, or simply “context” for short, is represented by one or more unique identifiers that enable linkage between the client-side and the server-side of each transaction.
Without context-propagation, distributed tracing is simply impossible as there is no reliable way of linking transactions together in a way that preserves their context.
Below is a simple example of context linking two transactions together. In this example, we use a context header containing two fields, transaction ID and parent ID. These two identifiers can subsequently be used to link two parts of a transaction.
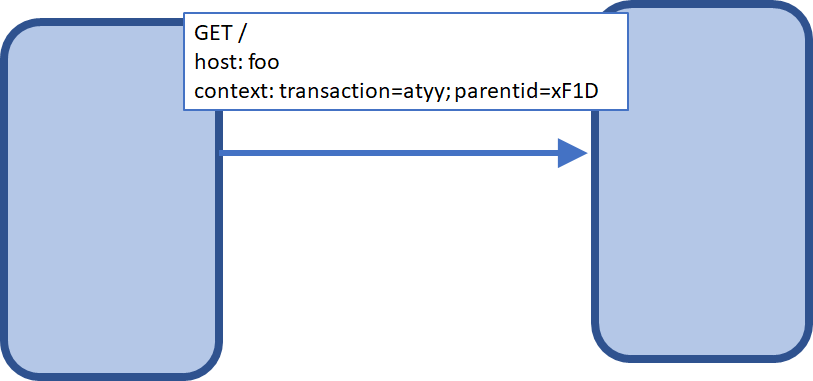
The passing context within HTTP headers enables linkage between distributed traces
Why context propagation breaks
Up to this point, the concept of Trace Context sounds pretty straightforward. It seems that all you need to do is forward a simple header — then distributed tracing works out-of-the-box, taking care of the details for you. Unfortunately, it’s not this simple. In the real world, some challenges must be addressed before distributed tracing can be deployed successfully within distributed environments.
There is currently no agreement on what these tracing headers should be called. Each tool vendor uses its own HTTP header to store context information. This wasn’t an issue in the past, as traces were rarely monitored by multiple tools. Today, things are much different. In many cases, cloud applications are monitored at the application level (by application developers) and by the cloud vendors. If different tracing headers are used in such scenarios, traces are likely to break when they cross the boundaries of the respective tracing tools.
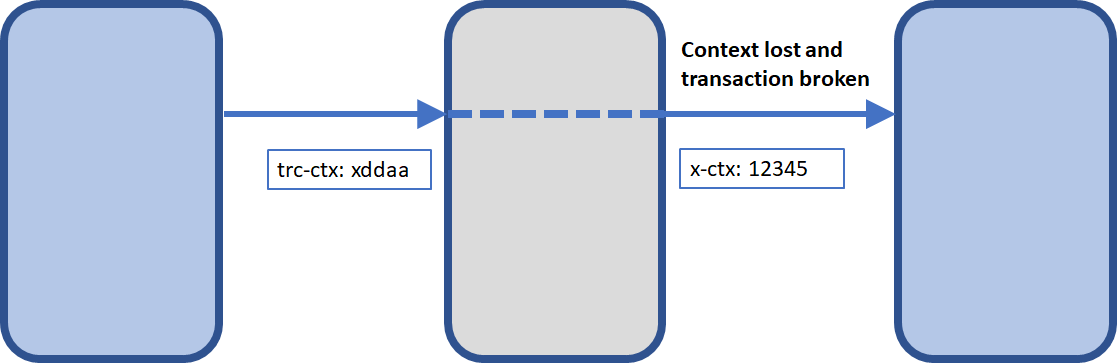
Transaction trace is lost because tools use different headers for context propagation
Incompatible tracing headers aren’t the only problem. As tracing headers aren’t standardized, they aren’t automatically forwarded by middleware such as routers, service meshes, or messaging systems. Again, when headers are dropped, traces break.
TraceParent: An agreed-upon header
The challenges detailed above are why tool providers have agreed on a new standard header called TraceParent. This header won’t be dropped as it’s recognized as a standard header that must be forwarded by tracing tools and middleware.
TraceParent might at first sound like a weird name for this header. Why not simply call it TraceContext? As always, there’s a story behind this. First of all, the Trace Context standard defines both the header itself and also the values that the header may contain. The TraceParent header accepts values that provide the essential information needed to enable distributed tracing: the transaction id and the parent id. Distributed traces can be reconstructed based on these two provided values. So, as the header identifies the parent, TraceParent isn’t such an odd name after all.
For completeness, it’s worth mentioning that a third part of the tracing header defines the sampling behavior that determines which traces are captured (or not). This information is required as most tracing systems only capture a fraction of overall traces. This information must be communicated to ensure that tracers within different application tiers capture the right traces and don’t create too much overhead by capturing traces that will later be discarded.
Also, TraceParent isn’t the only header used for tracing. There’s a second header called TraceState.
TraceState: Going beyond parent correlation
The Trace-Parent header enables parent-based correlation for the reconstruction of distributed traces. At first glance, this appears to be everything we need to maintain transaction context within distributed applications across tools. However, most implementations require more information than what can be defined within a TraceParent header (for example, tenant data within a SaaS environment and other information a system needs to optimize the routing and processing of data).
Using the TraceState and TraceParent headers in combination enables tools to collaborate on creating distributed traces as tools can then rely on all information being properly forwarded.
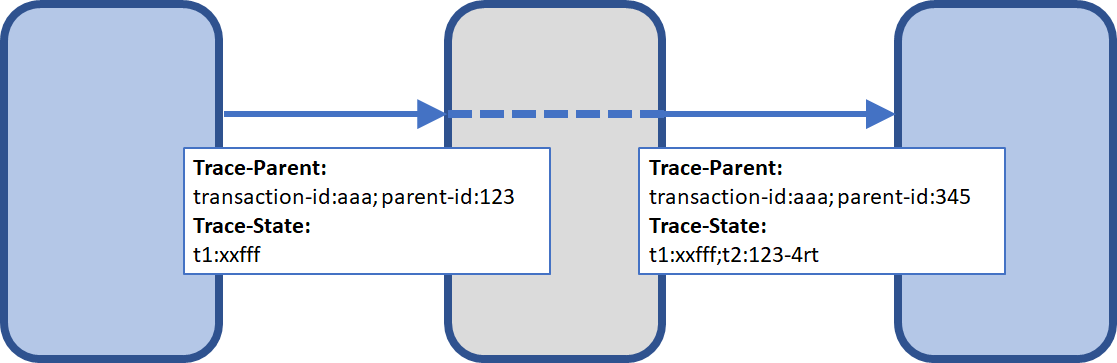
With standardized headers, traces don’t break (even for proprietary information)
Tracing beyond backend systems
While trace context has primarily been defined to enable tracing within distributed server-side systems, it’s in no way limited to this. The advantages of starting traces on the client side in the browser are obvious. With this approach, instead of receiving only end-to-end traces that begin at the web server, you can instead receive traces that begin when a user initiates a transaction in the browser.
This is already possible today, but there are no standardized means for forwarding this tracing information, resulting in the same challenges detailed above. So, eventually, trace context must be extended to the browser.
The TraceContext specification
In short, the Trace Context specification is a collection of standardized HTTP headers that allow distributed tracers to communicate without dropping context information. Having the standard in place will enable a milestone in improved visibility for developers and operators of distributed systems. TraceContext will only be the first specification that enables more interoperability between tracing systems. An obvious next step is an agreed-upon data format combining tracing information collected from different tools.