
Why our development teams don’t use microservice frameworks
Frameworks like Spring Boot can get you started easily, but they might be counterproductive in certain contexts.

It has become standard in the industry to support a microservice architecture with the help of frameworks such as Spring Boot, Micronaut, Quarkus, etc. And why shouldn’t it be?
Microservice solutions are complex enough, using a framework to support your development just makes sense.
Or does it?
The general mindset is that building upon a framework helps you be more efficient and make it easier to build complex solutions. Let me explain why this is not a universal truth and, in some contexts, like ours at Dynatrace, it’s better to go without.
Why is our context different?
Dynatrace is built upon dozens of running services and counting. Many of them are built in parallel by an equally growing number of teams. A one-size-fits-all framework like Spring Boot would help us with getting started quickly. However, in the long term, with not every developer understanding what’s happening under the hood, we’d lose control of the whole architecture.
In our SPINE project, we have a team that focuses on creating a “Dynatrace-flavored” microservice framework built around standard libraries (Jersey, Jackson, MyBatis, etc.) called “spine-commons”. Its goal is to provide developers with ways of doing things, while still enabling them to understand how everything is connected underneath.
Building a purpose-built framework is not what makes us more efficient, using it does. We have the resources to build on top of something that we have under our control and to move at our own pace, and I’m convinced it’s well worth the investment.
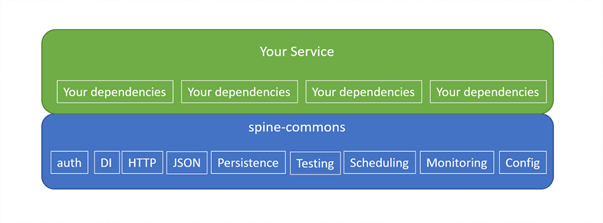
Our vision for the perfect framework is of one that allows us to stay in control of our project and educates everyone on how to grow the codebase. Enabling you to build code that stays maintainable over the years.
Just to clarify…
This blog post is about frameworks and not about libraries.
A library deals with specific use-cases, i.e., connection pooling, logging, string manipulation, etc. They are something you use. It’s easy to switch from one library to another — you only need to change the code that uses it.
Frameworks are made up of libraries, yes, but it’s something you build upon. You rely on a framework for fundamental parts of your application. Replacing a framework requires you to change most of your code.
So, let’s look at some of the reasons why we are pushing for the creation of our framework that suits our needs, instead of using something “ready-made”.
Frameworks make it easy to build complex solutions
This one may sound a bit counter-intuitive: if frameworks make things easier, why not use them?
Well, most frameworks make it easy for developers to solve problems by throwing technology at them.
For example: caching.
Just add @Cache to any method definition and the framework takes care of caching that method call. This is great if you really need a cache. But if you just add cache without thinking, you won’t invest time exploring the performance problem underneath. How does this cache implementation work? Is it fine for production use?
It’s a single line of code that may require more configuration and testing behind the scenes. Meaning that you may just be shifting a problem around for somebody else to solve, without fixing the real issue behind it.
Scaling to more than a thousand developers means educating more than a thousand developers
To be able to deliver value, every Dynatracer needs to know how the microservice they are working on looks under the hood. They need to learn how code is structured properly to maintain it, even with new developers joining every month.
What benefits does this bring? As an example, although wiring components is a tedious task, every developer will learn how to do this in the long term, and it will become core competence of every developer at Dynatrace.

Automatic dependency injection can lead to problems
It’s quick and easy to add @Inject or @autowired to have an instance of any class at hand in any class. But since it’s so easy to do, it doesn’t require you to think about different types of classes. The framework doesn’t care if a class needs to be instantiated first or at runtime, for example, and it just does everything in the right order. Until it doesn’t. Been there, debugged that.
Dependency Injection itself is great, however, there are other ways other than @Inject. For instance, you can just have constructor parameters to add your dependencies.
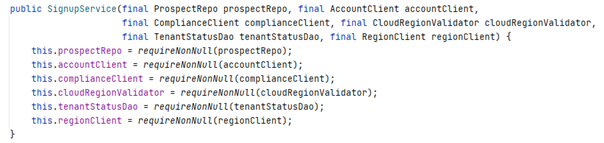
A long list of constructor parameters might annoy you. But there’s a positive aspect about that: in this way you realize how many dependencies your class has. And smart developers like you will immediately recognize that you can split this class. Because you’ve been growing it to the point where it covers multiple responsibilities, not just one.
No framework can give you this information. Au contraire: this is exactly the type of complexity, which is abstracted away from you, effectively luring you into even more complexity.
To be fair, this would be a different story if we were talking about monolithic codebases with millions of lines of code. But in our today’s architecture built upon smaller components (i.e., microservices), I expect codebases in maintainable sizes. And if you feel like your microservice is getting too complex to maintain manually, maybe this is the time to think about splitting it into two microservices.
Keeping codebases under control is a skill every developer needs to train
If we want to live DevOps fully, we need to make sure that our developers have the right skills to deploy and operate, not only write code. And this includes keeping the complexity of codebases under control as they grow.
Messed up dependencies, unclear responsibilities between classes, no separation between business logic and boilerplate, etc. make the difference between maintainable codebase and dreaded “legacy” code. If developers need to think about these topics every day while developing, they will in the long term be well-trained in handling them.
To summarize
These are just a handful of reasons why we have decided to not use common frameworks for certain projects at Dynatrace. Some projects do use them, but we are also trying this other approach and it seems to work very well.
There are more reasons that I haven’t addressed, but in the end, the key message I wanted to convey is that using frameworks at the base of your software is not going to solve every issue you have. Depending on your context, it makes sense to use them to get started quickly and solve problems easily. But for certain contexts, it makes more sense to take the harder route and look under the hood to gain more in the long run.
Why our development teams don’t use microservice frameworks was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.