
Shifting SRE Left with Keptn
Keptn’s Lighthouse Service is at the center of analyzing SLIs and SLOs as part of delivery

Site Reliability Engineering (SRE) is a concept that has been present in the IT community for over a decade, and it’s an idea that has helped many companies improve their operations in production to make their infrastructure code more reliable and scalable.
By developing the open-source software keptn, we are proposing the idea of taking SRE concepts and shifting them further left into delivery while simultaneously answering the question: How can you ensure delivering code that complies to every standard you set, test it in every stage but without slowing you down with manual work?
What is Site Reliability Engineering?
Before we talk about the keptn approach, let’s have a short refresher on what Site Reliability Engineering (SRE) actually is.
SRE is a well-known buzzword coined in 2003 by Google VP of Engineering Ben Treynor Sloss. It describes the idea of “applying the principles of software engineering, which are used to create highly reliable and scalable software, to the operations and infrastructure processes”. This approach helps maintain large systems with the help of infrastructure code that for system admins is more scalable and sustainable.
The two main concepts of SRE models are standardization and automatization. You take over the tasks that are usually done manually by the operations team and automate them based on certain standards. Its goal is to turn traditional monolithic operations into something that is more flexible and reliable for cloud-native or microservices-based software.
At the base of SRE we have three main concepts, SLIs, SLOs and SLAs, which build upon each other:
Service Level Indicators (SLI)
- These are measurable metrics that can be used as a base for an evaluation.
- Example: Error rate of Login requests.
Service Level Objectives (SLO)
- These are binding targets for SLIs (what the value of an SLI should be to be considered successful).
- Example: Login Error Rate must be less than 20% over a 30-day period.
Service Level Agreements (SLA)
- These are business agreements between consumer and provider typically based on an SLO.
- Example: Logins must be reliable & fast (Error Rate, Response Time, Throughput) 99% within a 30-day window.
In short: SLIs drive SLOs which inform SLAs
SRE in practice
Many companies have already put the SRE approach in place in production. We have seen this happening with Dynatrace clients who defined SLIs in production using the Dynatrace monitoring tool. This approach has delivered great results because it makes sure that the production maintains the standards set by the company.
However, we have also seen that setting standards only for production may cause deployments to slow down. Sometimes code is deployed from dev to staging without issues but is blocked in production because it does not meet the same requirements.
Furthermore, in a traditional pipeline, there always comes a stage where you run many types of tests, like performance, functional, monitoring, etc. But at this stage, these results either need to be analyzed manually or you need to build your own tools for it. And this slows down the pipeline even more.
Shifting SRE left with keptn
If we take the concept of SRE and evaluate SLOs already in every pipeline run, build or commit done in dev and staging environments, we can make sure that only code is deployed that complies with your standards. But this can only work if we fully automate those checks.
This is what keptn proposes to do with the core service Lighthouse a.k.a. Quality Gates.
But before we talk about this in more detail, let’s quickly talk about what keptn is and does.
With our open-source software project keptn we strive to simplify the traditional delivery pipeline and make it more manageable for cloud-based software.
A traditional delivery pipeline is often made up of lots of interdependent code that is hard to maintain and update. Because they have high interdependencies, traditional pipelines are bulky, resist change and slow down delivery. This is what makes us believe that they will become your next legacy-code challenge.
Keptn breaks up the pipeline into smaller phases: micro-pipelines (just like breaking up monoliths into microservices). Each phase is encapsulated in itself and communicates with other phases through interfaces in the form of events. There is a start event that contains the necessary data to execute the phase and an end event that represents the result of the phase.
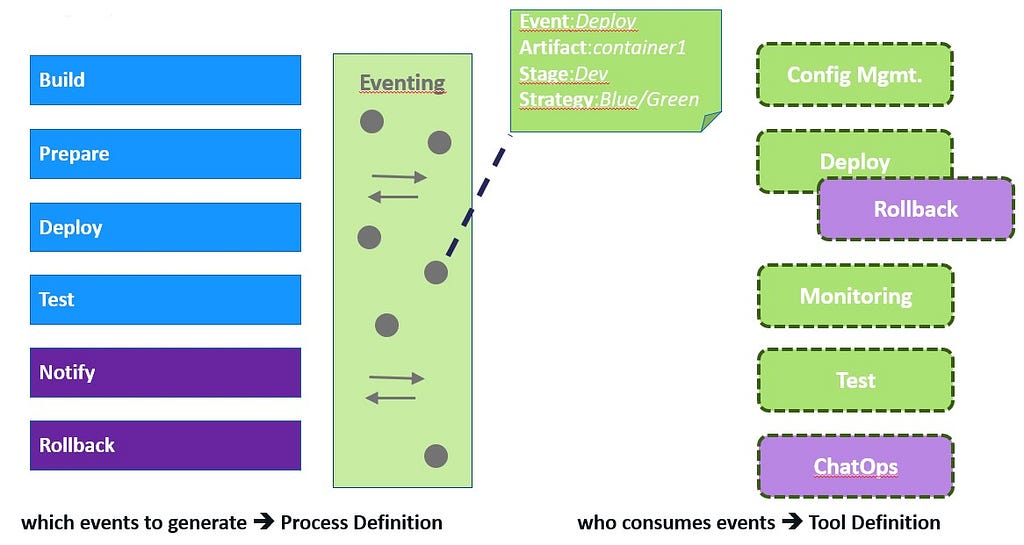
The keptn approach is to use a publish-subscribe mechanism, which allows you to subscribe to the relevant event types you need in the pipeline. The events that are sent control the workflow and how the events are processed controls the tooling.
This makes it easy to add and remove tools in your pipeline. There are no hardcoded integrations: the tool provides the functionality, and you can trigger it through an event. Once you set up a project, you need to define your pipeline in what we call a “shipyard” file that is saved in keptn’s internal git repository.
Here is an example:

As you can see, we defined a delivery process with dev, staging and prod stages, and for each stage we also defined what should happen. In “staging”, for example, we defined an automatic approval strategy, we run performance tests and the deployment strategy is “blue-green”.
Keptn will automatically create for every stage a git branch based on what is defined in this YAML file. And now the previously mentioned Lighthouse service comes into play.
Just like in shipyard.yaml, you define certain metrics in SLI and SLO YAML files against which data should be evaluated. Here is an example of what these SLI and SLO files may look like:
SLIs defined per SLI Provider as YAML
SLI Provider specific queries, e.g: Dynatrace Metrics Query

SLOs defined on Keptn Service Level as YAML
List of objectives with fixed or relative pass & warn criteria

The Lighthouse reaches out to your preferred monitoring platform through an event (right now we have integrations for Dynatrace, Prometheus, Neoload, Wayfront — but you can develop any integration you want or need) and returns the data for a particular timeframe.
Keptn looks at this data, evaluates it against the metrics, gives points and then sums up a total score based on the total number of SLIs and normalizes it between 0 and 100%.

Keptn comes with pre-configured SLIs and SLOs, but you can further configure them yourself either through a YAML file or through a dashboard.
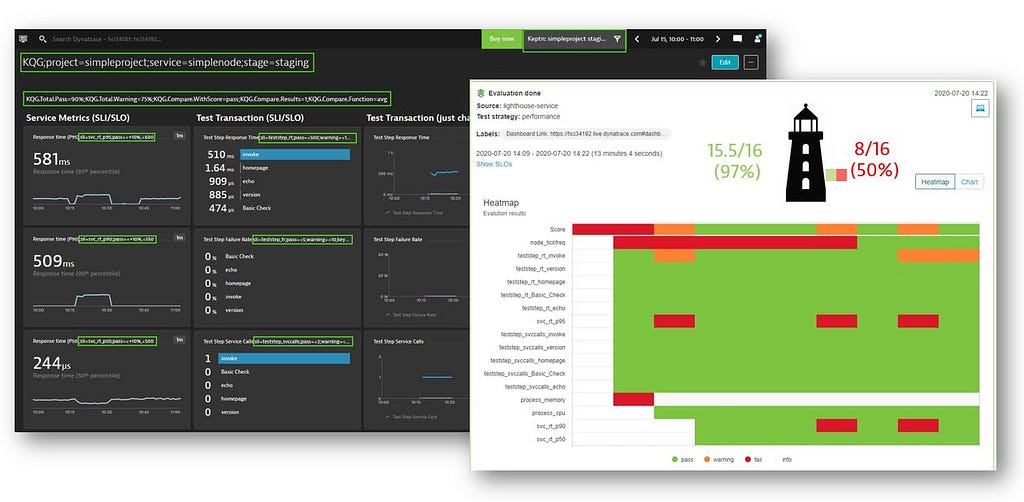
Now that it’s set up, every time keptn executes a process, makes a configuration change, an auto-remediation, or a test, we always re-evaluate the SLIs and SLOs by reaching out to the monitoring tools. By doing this, we implement this core SRE concept of automatization and standardization not only in production but also in delivery.
Apply SRE to your own delivery pipeline
Site Reliability Engineering is very valuable for the production of safe, reliable and scalable infrastructure code, and it is a concept that is applicable in delivery as well as in operations.
Try it out yourself and learn more about keptn by joining our open-source community: https://github.com/keptn.
We are always looking for motivated developers and DevOps engineers who would like to contribute to creating a new way of doing delivery and operations.
If you’d like to know what other integrations we are working on at the moment, check out our contribution and sandbox spaces on GitHub.
Keptn also has its own publication on Medium, be sure to check it out to keep up to date with our work: https://medium.com/keptn
Shifting SRE Left with Keptn was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.