
JumpBackHash: Say Goodbye to the Modulo Operation to Distribute Keys Uniformly to Buckets

Distributed data processing and storage requires a strategy for mapping tasks or data across available resources. In more abstract terms, the strategy must be able to distribute keys to a given number of buckets. Ideally, the keys are uniformly assigned to the buckets to achieve a balanced utilization of resources. If there are 𝑛 buckets labeled 0, 1, 2, . . . , 𝑛 − 1, a prevalent and straightforward pattern to map a key to a bucket index is to take the remainder after dividing the hash of the key k by the number of buckets 𝑛. The following Java code snippet illustrates such approach:
int getBucket(long k, int n) {
return (int) ((k & 0x7FFFFFFFFFFFFFFFL) % n);
// mask to ignore sign bit and to ensure a nonnegative result
}We assume that the hash value of the key 𝑘 is the result of some high-quality hash function, such as WyHash, KomiHash, or PolymurHash, and can be considered as a random value. Further, suppose that the number of buckets is much smaller than the maximum possible hash value, which is usually the case for 64-bit hash values. Then, the keys will be uniformly distributed over the buckets as desired.
What is the problem?
Unfortunately, with the modulo-based approach, a change in the number of buckets 𝑛 will also change the mapping of nearly all keys. If 𝑛 is increased to 𝑛 + 1, every key will be mapped to a different bucket with a probability of 𝑛/(𝑛+1), meaning nearly all keys get reassigned for large 𝑛. The same is true if the number of buckets is reduced. All those reassignments would happen simultaneously and cause pressure on a distributed system. For example, this might lead to a timely concentrated higher network load as data needs to be shifted to other physical instances. This could also result in a short-term increase of database requests to load key-specific settings or missing cache entries, which may cause backpressure on data streams as a further consequence.
The solution: Consistent hash functions
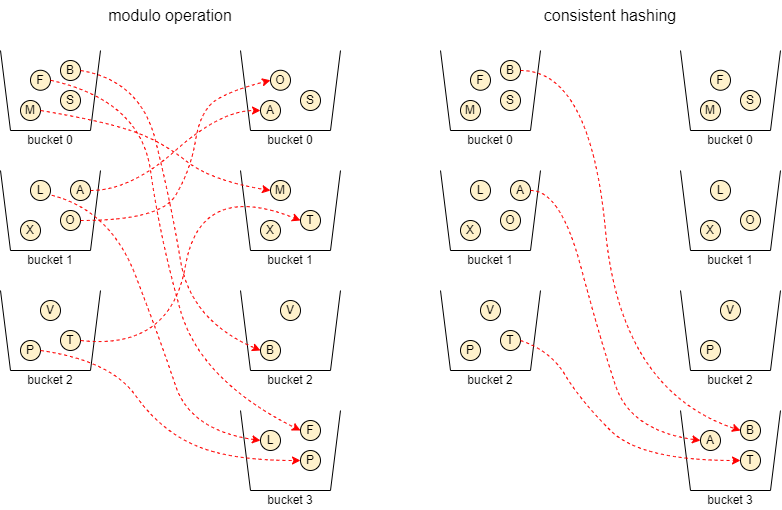
Consistent hash functions can be used as a replacement for the modulo operation to distribute keys uniformly to buckets. They minimize the number of keys reassigned to a different bucket to restore balance. On average, only 1/(𝑛+1) of all keys must be mapped to a different bucket when the number of buckets is increased from 𝑛 to 𝑛 + 1. This is a massive improvement over the modulo approach. The illustration below shows an example of how the mapping of 11 objects changes after increasing the number of buckets from 3 to 4 when applying the modulo operation on the key hashes and when using consistent hashing to minimize the number of reassignments.
State of the art: JumpHash
A widely used consistent hash function is JumpHash. It is deterministic, based on a standard pseudorandom number generator, and its implementation is simple:
int getBucket(long k, int n) {
randomGenerator.resetWithSeed(k);
int b = -1;
int bPrime = 0;
while (bPrime < n) {
b = bPrime;
bPrime = (int) ((b + 1) / randomGenerator.nextDouble());
}
return b;
}It uses a hash of the key k to seed a random generator, which is then used to produce a sequence of random values until the loop’s stop condition is satisfied. The loop is left on average after approximately ln(n) iterations, meaning the execution time scales logarithmically with the number of buckets n. As the implementation is also very compact and needs only a standard pseudorandom generator, which can be found in most standard libraries, JumpHashCode has become very popular. For example, it is used by Booking.com for their customer review system.
Depending on the system and chosen pseudorandom generator, execution typically takes around 100 nanoseconds on modern CPUs for thousands or millions of buckets. This is fast but still significantly slower than a modulo operation. Furthermore, floating-point division may be problematic for devices without corresponding hardware support.
Our proposal: JumpBackHash
We have developed a new consistent hash algorithm called JumpBackHash, as presented in a recent research paper. It is faster than JumpHash, has a bounded expected execution time independent of the number of buckets, and can even compete with the speed of the modulo-based bucket assignment. Furthermore, JumpBackHash does not require floating-point arithmetic, making it suitable for low-power devices. As JumpHash, it only needs a standard pseudorandom number generator and can still be compactly implemented according to this Java code snippet:
int getBucket(long k, int n) {
if (n <= 1) return 0;
randomGenerator.resetWithSeed(k);
long v = randomGenerator.nextLong();
int u = (int) (v ^ (v >>> 32)) & (~0 >>> numberOfLeadingZeros(n - 1));
while (u != 0) {
int q = 1 << ~numberOfLeadingZeros(u);
int b = q + ((int) (v >>> (bitCount(u) << 5)) & (q - 1));
while (true) {
if (b < n) return b;
long w = randomGenerator.nextLong();
b = (int) w & ((q << 1) - 1);
if (b < q) break;
if (b < n) return b;
b = (int) (w >>> 32) & ((q << 1) - 1);
if (b < q) break;
}
u ^= q;
}
return 0;
}Benchmark Results
We measured the performance of JumpBackHash and JumpHash using the fast and well-tested SplitMix algorithm as a pseudorandom number generator for both to allow a fair comparison. In addition, we considered bucket assignment using the modulo operation. The results obtained on an Amazon EC2 c5.metal instance with disabled Turbo Boost (P-state set to 1) for different numbers of buckets are plotted below.
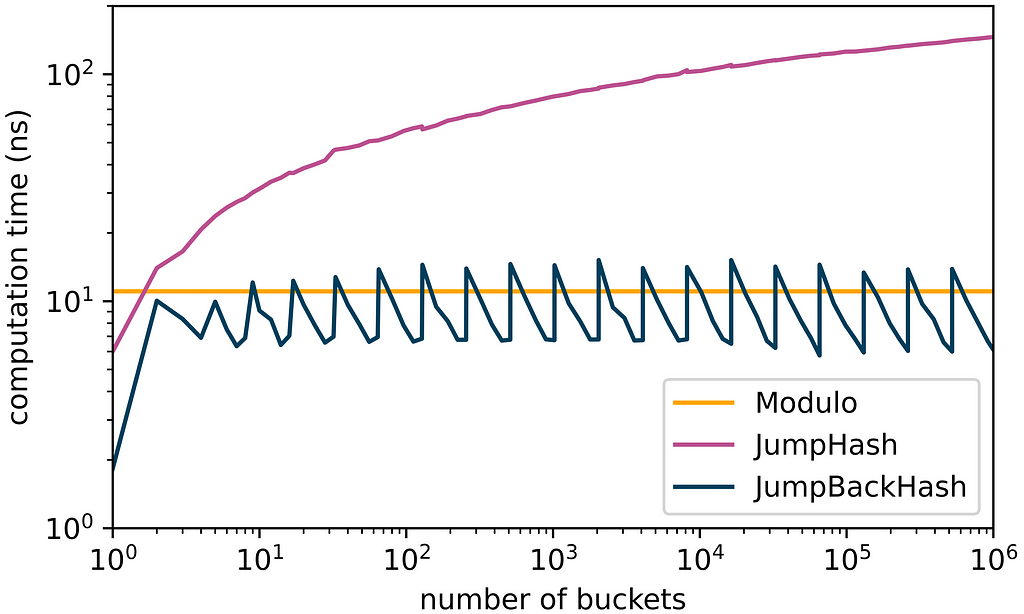
Our measurements show that JumpBackHash is always faster than JumpHash. While the computation times of JumpHash scale logarithmically, those of JumpBackHash are bounded by a constant independent of the number of buckets and are even comparable to the modulo-based assignment because the modulo operation is generally quite expensive due to the involved integer division. JumpBackHash is particularly fast if the number of buckets is close to the next power of two, which explains the sawtooth pattern.
Conclusion
In summary, there is no longer a good reason to distribute keys by applying the modulo operation on the hashed key. JumpBackHash achieves a similar speed but gives assignment stability of a consistent hash function for free. This can improve your overall system stability during critical phases when resources get added or removed, planned or unplanned. A production-ready implementation of JumpBackHash was released as part of our open source Hash4j Java library under the Apache 2.0 license.
JumpBackHash: Say Goodbye to the Modulo Operation to Distribute Keys Uniformly to Buckets was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.