
Incidents are the new normal
Let’s normalize incident reviews in software development
Why are incidents the new normal? Because if there’s anything that our decades of experience in software development have shown us, it’s that things are going to fail. There’s no doubt anymore about whether it will happen. We need to start asking when it’s going to happen.
Only in the past year, we’ve seen bugs and incidents take down some of the best-known companies: think of Facebook’s data leak in April or AWS’ Data Centre outage in June. And if it happens to FAANG companies, it indeed can happen to anybody even if you use every best practice in existence to prevent them.
So, if you can’t depend on prevention to 100%, what should you do? You can learn from mistakes by conducting incident reviews after they’ve happened.
What’s an incident review?
An incident review is a meeting that happens after an incident has been fixed to review why an incident occurred and what can be done to be more prepared for it in the future. The goal is not to point fingers and blame somebody; it’s about finding a solution together as a team.
Some may call this a post-mortem, but I don’t think this term is accurate because “mortem” refers to death. In most cases, a system or software will still be alive after an incident happens.
How do you conduct an incident review?
So, you got a call in the middle of the night because of an incident, and you worked for hours and hours to get everything back in order. It was hard, but you did it thanks to the help of your team and everybody involved.
As Winston Churchill said, it’s essential to “never let a good crisis go to waste,” so you see this as an opportunity to analyze what happened and learn from it. That’s why you decide to set an incident review meeting for the next day.
But where should you start?
Step 0: Choose a facilitator
Before you start, you should select somebody to facilitate the meeting. Ideally, it should be a colleague who’s not part of your team and is good at moderating and enabling discussion (like an Agile Coach). It should not be the person who found and fixed the bug or anybody who had high stakes with it because this can affect the neutrality of the meeting.
1st step: Gather metadata & create a timeline
First, you should gather all the information that you possibly can about the incident. Gather all the facts, events, descriptions, dashboards, logs, monitoring data into one place.
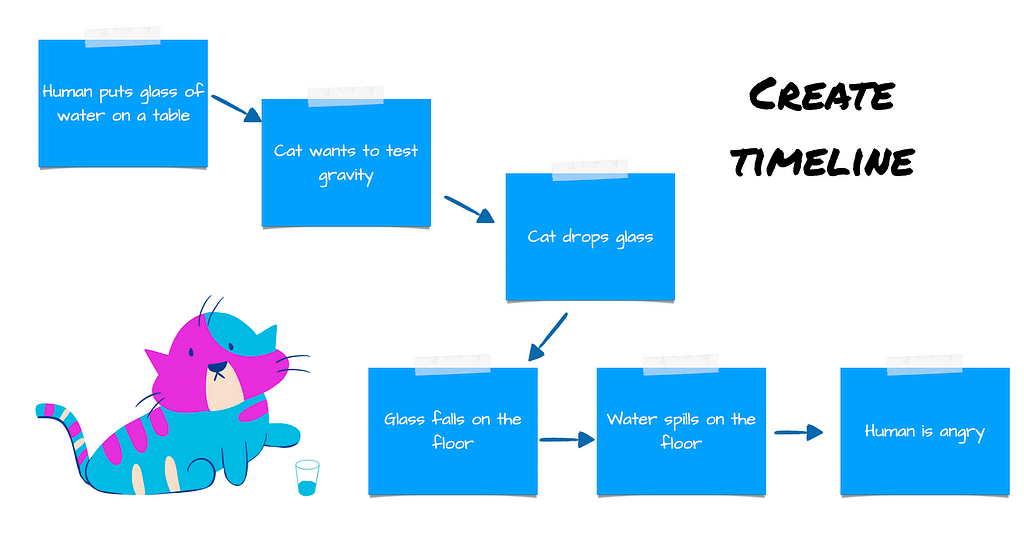
If you have simple projects, using a whiteboard and some sticky notes is enough to get an overview of what happened.
If you have a more complex project, you can use a tool like Dynatrace that creates a timeline from the infrastructure’s perspective first. Then take this timeline and use it as a base for further analysis.

The timeline should be set up by the review facilitator and participants should add all the missing information to create the big picture. When you have a base to start from, begin asking questions.
2nd step: Ask questions and find causal factors
Start talking with participants about the different steps in the timeline and discover the stories behind the incident. Ask questions that encourage discussion, i.e., open-ended questions.
Don’t ask, “When did you discover that the service was down?” Ask instead: “How did you discover that something was broken?”
When you are facilitating, it’s important to look for descriptions, not explanations. When an assignment is done, you can start looking for causal factors or contributing factors. These are actions or events or lack thereof that lead to the incident or worsened its effects. It’s important to point out that one causal factor alone doesn’t cause a big incident. There are always smaller factors that combine to create a perfect storm: insufficient testing, not enough detailed monitoring, etc.
Then we need to go deeper and search for everything that allowed for the mistake to happen by using the 5-whys/hows technique.
Imagine that engineers detected a problem. They performed a rollback to the previous version, but the rollback didn’t help, and they ended up breaking even more stuff. So, when you ask them why they tried the rollback, they tell you that this is the standard procedure when production is down. They will also describe their external sources of pressure and how they coordinated the on-call. So, we can gather all this information about how this happens and what conditions allowed it.

A single root cause does not exist. Our systems are made out of many parts that work perfectly in isolation, but still, incidents could happen due to very weird interactions between working parts.
3rd step: Create action points (optional)
After reviewing the circumstances leading up to an incident, the next logical step is to create some action items to prevent this from happening again. However, defining action is optional.
In the past, I thought that every incident review should end with defining actions. Still, the reality is that it’s sometimes better to decide not to implement any measures because they can incur high expenses. And sometimes, well-meaning actions also get forgotten and never implemented.
We don’t increase our success by preventing things from going wrong. We do it by making sure things go right. Quality and reliability are business concerns, so each time you face an incident, we need to assess the risk and decide: can we handle the same incident twice?
It is important to remember that implemented actions don’t guarantee that our software won’t fail in the future, so it’s imperative to monitor activities as they work and check their impact on our development process.
The only mandatory action is to share your learnings. If you learn something new from the incident, share it! Document it, write a blog post, or hold a presentation. Teaching is the surefire way to understand what is going on in your system or your software. Learning from gaps highlighted by incidents can guide us in the direction in which our system should evolve.
Failure is an option
Our modern software products are built with the best quality we have historically achieved, but they still fail sometimes. With technologies and systems changing rapidly, it’s nearly impossible to keep up in every aspect, but that doesn’t mean that something should always break production.
Anyone who says that failure is not an option is either arrogant or ignorant of the complexity of many software systems. Failure is an option because we don’t get to choose the fight. It’s going to happen. If we try to prevent all fights, we would never move forward, and we would miss out on many learning possibilities, which would be even worse in the long run than facing an incident in the short term.
Why are incidents the new normal? Because we fail fast and move forward.
Incidents are the new normal was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.