
How to combine and automate infrastructure and application deployment in a microservice environment
A collection of best practices to improve your confidence in your deployed applications.

When we read about continuous delivery and microservices, everything sounds like a fairytale. Start writing your service, put some CI-magic around it and deploy it to your dev, staging, and production environment with the CD tooling of your choice. The infrastructure part is often held out of the equation, which can become a serious issue throughout the lifecycle, especially in cloud environments. Although automation is possible from the moment you have proper observability in your environments, we often tend to require a human to “promote” or approve the results of tests. We often think it’s good to deploy our applications in a defined cadence, which might not be the best quality gate in practice. With the help of SRE practices and data collected in your observability platform, the confidence in automation and reliability is increased.
What you will learn about in this article
- The separation between Infra- and App-Ops
- Versioning Issues between those two worlds
- Data-driven deployments
- The difference between deploying and releasing
In this article, you’ll read about lessons I learned in the last few months in my continuous delivery journey and some suggestions about best practices to improve the confidence in your deployed applications.
About Infrastructure and Continuous Delivery
DevOps and NoOps are terminologies we often hear nowadays. Even though sharing responsibility for every building block of our application makes sense, there might be compliance requirements and other things that make us think that it’s safer to deal with our infrastructure separately and keep the tooling distinct. If cloud services are used to support microservices (as databases, storage buckets), precisely this separation might cause a lot of trouble.
One of the first problems, in this case, is the perfect point-in-time to apply such infrastructure changes. In our continuous delivery world, we don’t want to wait until a manual step before deploying a new version of our application (at least our automation won’t do so). Therefore, a typical PR-approval approach won’t work. This could lead to a situation in which a microservice needs infrastructure, which is not present and — if not correctly handled — can break the application deployment. For me, the most valid approach to solving this problem is a unified deployment workflow of infrastructure and the application to keep this consistent in both worlds.
Before starting application deployment, the platform itself (Kubernetes) needs to be prepared. As — most probably — many services share the same platform, it is not possible to bind it to a specific service. Therefore, the platform infrastructure code should be handled outside of the application scope. As described before, it might get problematic to keep platform and application code in sync. Therefore, we should consider the platform infrastructure as an additional — very lightweight — (micro-)service and define some contracts on which the application team can rely. They could include the following:
- Used (Kubernetes-)Versions
- Defined Storage Classes, Ingress Controllers, and available Priority Classes on the Cluster
- Networking constraints and service mesh availability
- Policies in place and service templates (also think of operators)
Using such contracts enables the feature teams to build their application infrastructure around this and ensures a minimal dependency between the feature and the platform team.
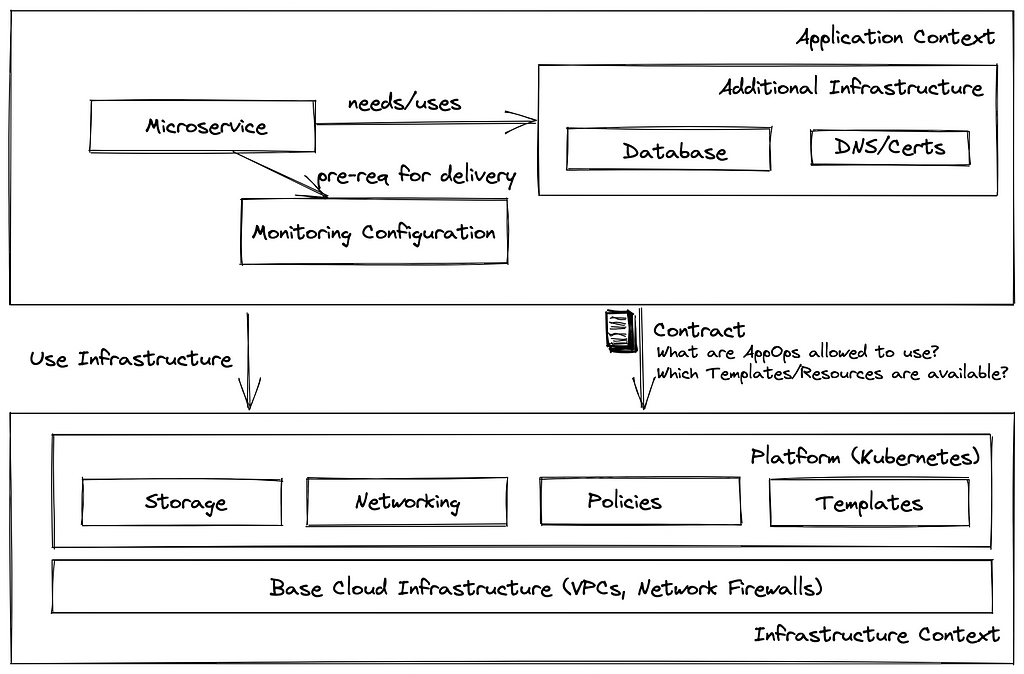
Infrastructure parts used by the feature teams will also be consumed and managed by them. Therefore, a team that requires a Database (e.g., MongoDB) in its microservice will also install and maintain this in CD workflow before application deployment. This ensures that there is enough infrastructure to operate this application. Finally, the platform team can control the usage of resources on the platform, and the cloud infrastructure by defining policies and templates. Using policies (e.g., in Open Policy Agent), you can define boundaries for microservice deployments. As an example, Platform operators could define policies enforcing that resource requests and limits are to be defined, and only images from trusted registries can be used. Templates (Crossplane compositions, Operators/CRDs) provide easy-to-use building blocks that developers can consume and control the way cloud and platform resources are used. A strict separation between infrastructure code and the configuration ensures that platform operators can test code changes the same way as application code (e.g., sizing, names). This progressive delivery approach ensures that changes on the infrastructure are tested very early and won’t break production.
Things discussed above will work most of the time, and it is possible to rely on contracts between application and infrastructure. Sometimes accidents happen, and an application or platform operator wants to avoid problems caused by missing infrastructure. For instance, an application configuration might use a specific Storage- or IngressClass, which does not exist on the Kubernetes Cluster and might get cumbersome when such an application is updated.
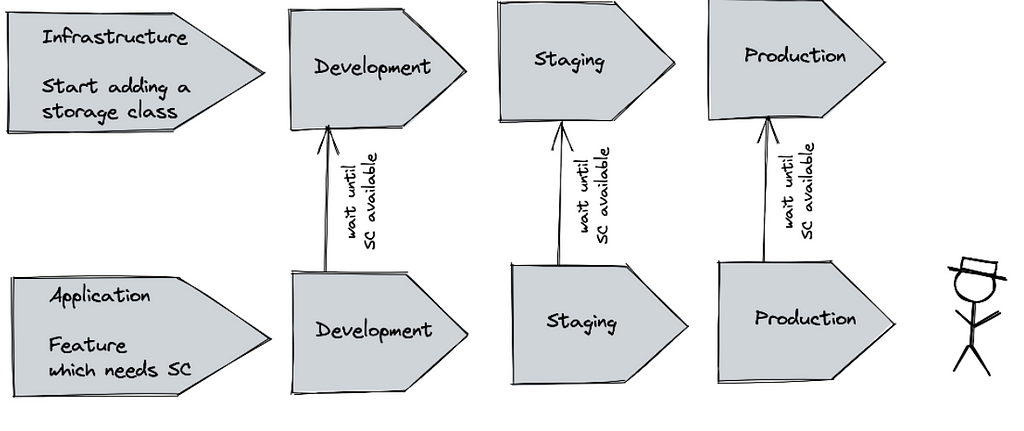
Another more problematic example would be using service templates that do not exist in the target environment. In this case, it could help to do some pre-flight checks to ensure that the infrastructure is available before doing updates. When using an operator-based deployment, it is possible to check and wait for prerequisites. Finally, the deployment can be canceled after a specific timeframe or executed when the requirements are met.
Data-driven deployment and releasing
There are many different opinions on the perfect time to deploy and release software. In the literature, we often read that we should deploy as often as possible and not make deployment a ceremony, which I agree with. Although this sounds very romantic, we should have enough confidence in our software to ensure that our customers get the perfect software they pay for. Therefore, we should run enough tests and collect as much valuable data during the delivery process to ensure this.
As I’m sure you are already doing enough testing in your CI pipeline, I will only cover the CD-related part here.
When deploying and releasing microservices, we often think about our bounded context and things that belong to our service. At first, the application gets deployed to a development-grade system, and we try to find out if it is deliverable and starts as we expect this. The later tests are executed, and the more manual the tests are, the more expensive they get. Therefore, every test in the CD workflow should be automated and as valuable and precise as possible.
So, which tests should be executed? For me, every test which gives us confidence in our deployed service (and doesn’t take too long) is helpful. Therefore, running smoke tests after deployment to ensure that everything is working as expected will be a good starting point. Furthermore, load and performance tests will ensure that the service sustains an expected load pattern. Moreover, load and chaos tests together could increase the confidence in the resilience of our system and ensure that it withstands “unexpected” events as pod crashes, node updates.
Most of the time, a microservice belongs to a more extensive system, and its behavior might impact (even if it should not) other services. Therefore, testing in a system context will ensure that other services will not break using the new version of the service. As a result, the new service version should be tested with a comprehensive set of end-to-end tests before pushing it to the next stage.
Even though we try to get more confidence into our current software deployment, the customer is the one who decides about the success of our software. Therefore, the most important metrics are the ones that are captured from the customer’s point of view. To achieve this, the application is monitored the whole time, and data is collected. For instance, the system’s behavior should not violate its Service Level Objectives when chaos is applied (so pods are deleted). By auto-scaling, the system’s conduct should not change on high loads. This can be achieved by integrating your observability platform into your CD workflow.
When thinking about the perfect time to deploy, it might be a good idea to deploy as fast as possible with as much confidence as possible. The deployment can be triggered after every successful CI-run on the main branch or tagging a commit with a version. To deploy software is not the same as releasing software. Therefore, we could deploy the newer application parallel to the old one, run some tests and shift the traffic (=release) if everything is ok (think of blue-green and canary deployments). Furthermore, we could base our release decisions on error budgets (see https://cloud.google.com/blog/products/management-tools/sre-error-budgets-and-maintenance-windows). Therefore, the CD tooling could check the error budgets in the observability platform and release when there might be enough remaining error budget to sustain problems when switching to the newer version.
Tooling
To achieve this, we are building precisely this use-case with the CNCF project Keptn as a control plane. This allows the integration of different tools under one umbrella and unifies the deployment experience for each microservice.
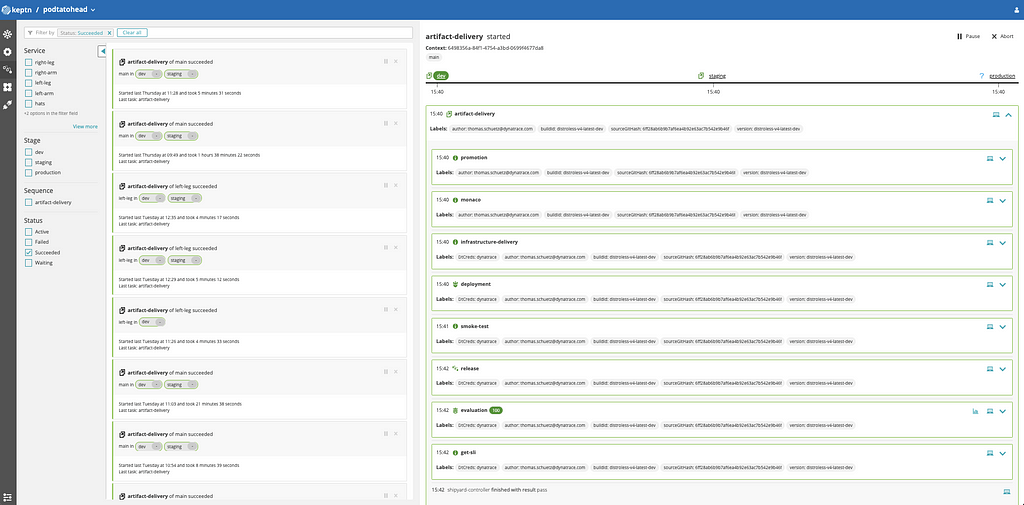
The screenshot above shows an example of an infrastructure-enabled Keptn sequence. At first, we configure our monitoring (Dynatrace Monitoring As Code). Afterward, the infrastructure gets updated, and the application is delivered. Finally, some smoke tests are executed, and tests run before raising a green flag to pass the deployment to the next stage.
Using this approach, it is possible to deploy applications and infrastructure together and have a clear contract between infrastructure and application operations. We can reduce the configuration drift between our code and the production environments by delivering applications as fast but as confident as possible. Finally, we can utilize SRE tools (as error budgets and SLIs/SLOs) to automate decisions and ensure that the quality of our service meets the customer’s requirements.
How to combine and automate infrastructure and application deployment in a microservice environment was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.