
Dynatrace Davis AI automatically monitors OpenAI ChatGPT for performance, reliability and cost
Businesses in all sectors introduce novel approaches to innovate with generative AI within their own domains. Advanced AI applications using OpenAI services will not just forward the user input to OpenAI’s models but require client side pre and post processing. A typical design pattern is the use of a semantic search over a domain specific knowledge base, like internal documentation, to provide the required context in the prompt. This is achieved by using OpenAI services to compute numerical representations of text data that eases the computation of text similarity, called embeddings, for the documents as well as for the user input.
Furthermore, tools like LangChain leverage large language models (LLM) as one of their basic building blocks for creating AI agents (think of AI agents as APIs that perform a series of chat interactions towards a desired outcome) which perform complex and potentially large queries against an LLM like GPT-4. They then connect to many other third-party services such as online calculators, web search, or flight status information to combine real-time information with the power of an LLM.
One of the crucial success factors for delivering cost-efficient and high-quality complex and potential AI agent services, with a path like one described above, is to closely observe their cost, latency, and reliability.
Dynatrace enables enterprises to automatically collect, visualize and alert on OpenAI API request consumption, latency, and stability information in combination with all other services used to build their AI application. This includes OpenAI as well as Azure OpenAI services, such as GPT-3, Codex, DALL-E or ChatGPT.
Our example dashboard below visualizes OpenAI token consumption, shows critical SLOs for latency and availability as well as the most important OpenAI generative AI service metrics, such as response time, error count and overall number of requests.
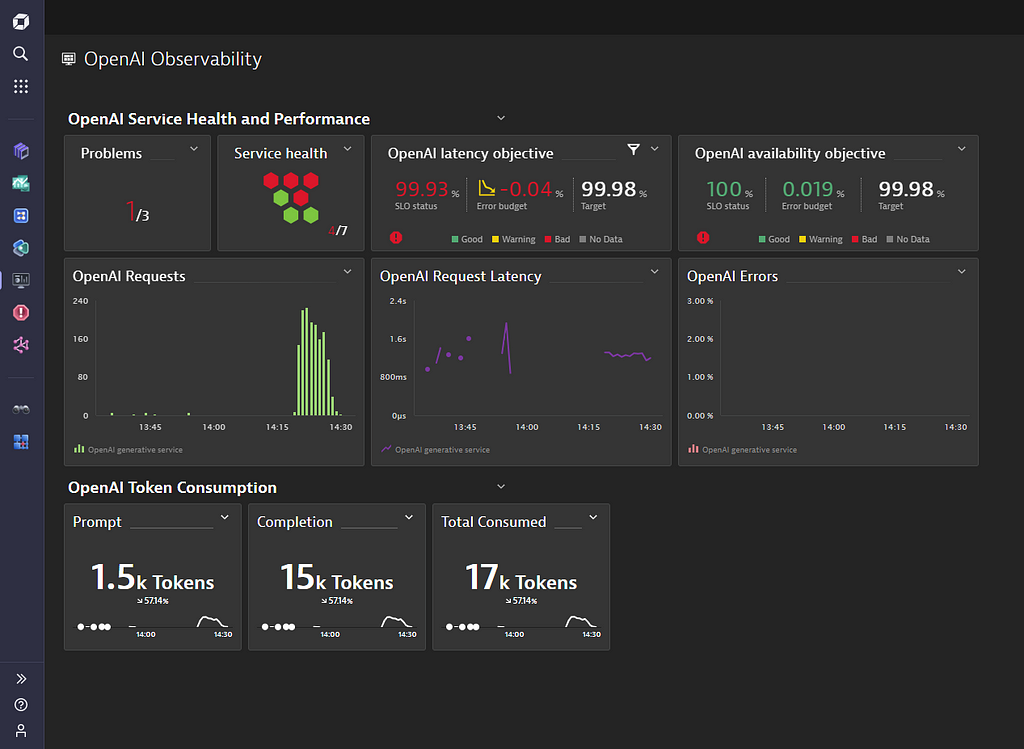
Dynatrace OneAgent discovers, observes and protects access to OpenAI automatically, without any manual configuration whatsoever, revealing full context of used technologies, service interaction topology, analyzes security vulnerabilities, and observes metrics, traces, logs and business events in real time.
Within this blog we will look at how Dynatrace automatically collects OpenAI/GPT model requests and charts them within Dynatrace, as well as how abnormal service behavior can detect slowdowns in OpenAI/GPT requests as root-cause of large-scale situations. Both functionalities have been part of Dynatrace platform for a couple of years now and have stood the test of customers’ experience.
How does Dynatrace trace OpenAI model requests?
We will use a simple NodeJS example service to show how Dynatrace OneAgent automatically traces OpenAI model requests. OpenAI offers an official NodeJS language binding that allows the direct integration of a model request by adding the following lines of code to your own NodeJS AI application:
const { Configuration, OpenAIApi } = require(“openai”);
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY
});
const openai = new OpenAIApi(configuration);
const response = await openai.createCompletion({
model: “text-davinci-003”,
prompt: “Say hello!”,
temperature: 0,
max_tokens: 10,
});Once the AI application is started on a OneAgent monitored server, it is automatically detected by the OneAgent and collects traces and metrics for all outgoing requests. Its automatic injection of monitoring and tracing code not only works for the NodeJS language binding, but also works in case of using the raw HTTPS request in NodeJS.
While OpenAI offers official language bindings only for Python and NodeJS, there is a long list of community provided language bindings.
The OneAgent can automatically monitor all C#, .NET, Java, Go and NodeJS bindings, while we advise following the OpenTelemetry approach to monitor Python with Dynatrace.
See below the traces that the OneAgent collects along with all the latency and reliability measurements for each of the outgoing GPT model requests:
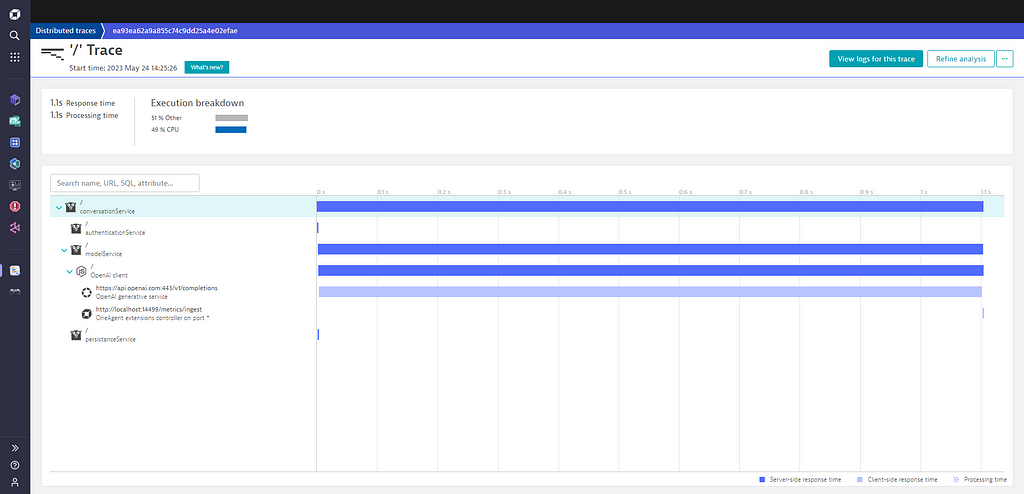
Dynatrace will further refine the OpenAI calls by automatically splitting specific services for the OpenAI domain, as it is shown below:
Once this is done, the Dynatrace ServiceFlow shows the flow of your requests starting with your NodeJS service and calling the OpenAI model, as it is shown in the screenshot below.
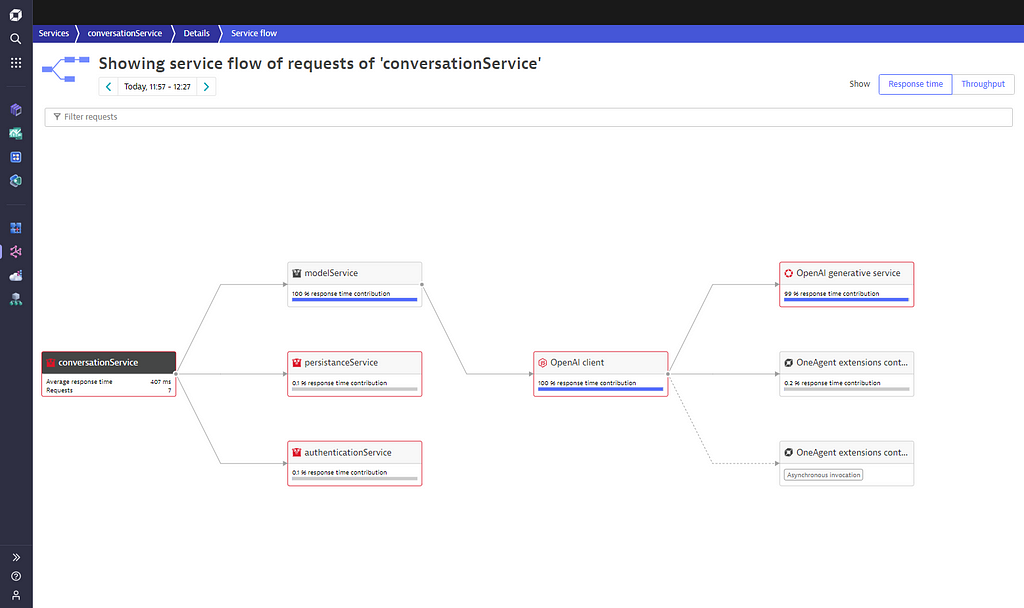
As shown in the example above, the Dynatrace OneAgent automatically collects all latency and reliability related information automatically along with all the traces showing how your OpenAI requests are traversing your service graph.
The seamless tracing of OpenAI model requests allows operators to identify behavioral patterns within your AI service landscape and to understand the typical load situation of your infrastructure.
This knowledge is essential for further optimizing the performance and cost of your services.
By adding some lines of manual instrumentation to your NodeJS service, cost related measurements will also be picked up by the OneAgent, collecting the number of OpenAI conversational tokens used.
Observing OpenAI request cost
Each request to an OpenAI model, such as text-davinci-003, gpt-3.5-turbo, or GPT-4 does report back how many tokens were used for the request prompt (the length of your text question) and how many tokens the model generated as a response.
Customers of OpenAI are billed by the total number of tokens consumed of all the requests they made.
By extracting those token measurements from the returning payload and reporting them through the Dynatrace OneAgent, users can observe the token consumption across all their OpenAI enhanced services in their monitoring environment.
See below the instrumentation necessary to extract the token count from the OpenAI response and to report those 3 measurements to the local OneAgent:
function report_metric(openai_response) {
var post_data = “openai.promt_token_count,model=” + openai_response.model + “ “ + openai_response.usage.prompt_tokens + “\n”;
post_data += “openai.completion_token_count,model=” + openai_response.model + “ “ + openai_response.usage.completion_tokens + “\n”;
post_data += “openai.total_token_count,model=” + openai_response.model + “ “ + openai_response.usage.total_tokens + “\n”;
console.log(post_data);
var post_options = {
host: ‘localhost’,
port: ‘14499’,
path: ‘/metrics/ingest’,
method: ‘POST’,
headers: {
‘Content-Type’: ‘text/plain’,
‘Content-Length’: Buffer.byteLength(post_data)
}
};
var metric_req = http.request(post_options, (resp) => {}).on(“error”, (err) => { console.log(err); });
metric_req.write(post_data);
metric_req.end();
}After adding those lines to your NodeJS service, three new OpenAI token consumption metrics are available in Dynatrace, as they are shown below:
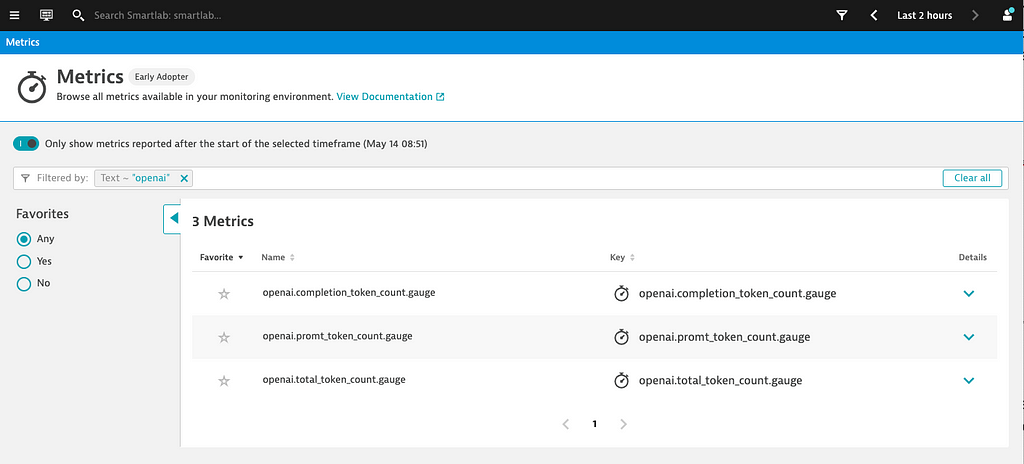
Davis AI automatically detects GPT as root-cause
One of the superb features of Dynatrace is its Davis AI automatically learning the typical behavior of monitored services.
Once an abnormal slowdown or increase of errors is detected, the Davis AI triggers a root-cause analysis to identify the cause of complex situations.
Our simple example of a NodeJS service entirely depends on the ChatGPT model response. So, whenever the latency of the model response degrades or the model request returns with an error, Davis AI will automatically detect that.
See below an example where Davis AI automatically reported a slowdown of the NodeJS prompt service along with correctly detecting the OpenAI generative service as being the root-cause of this slowdown.
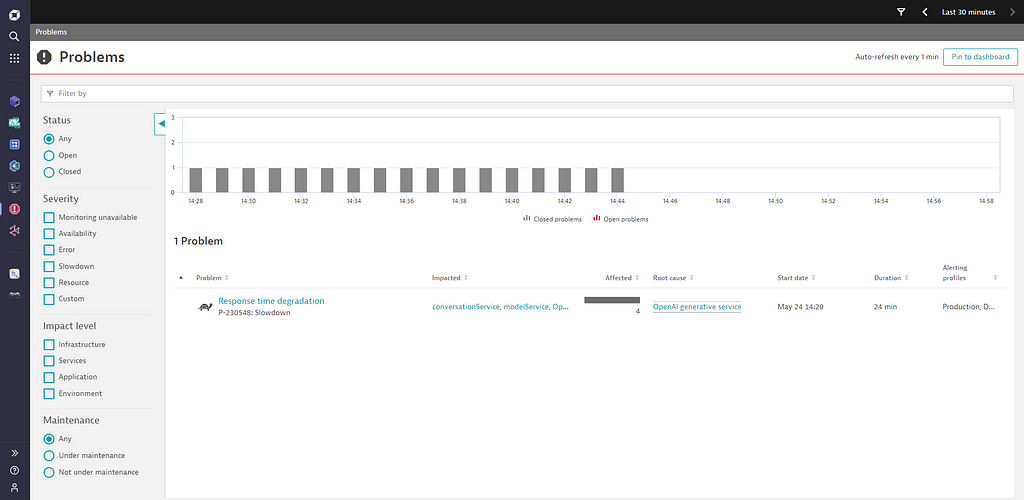
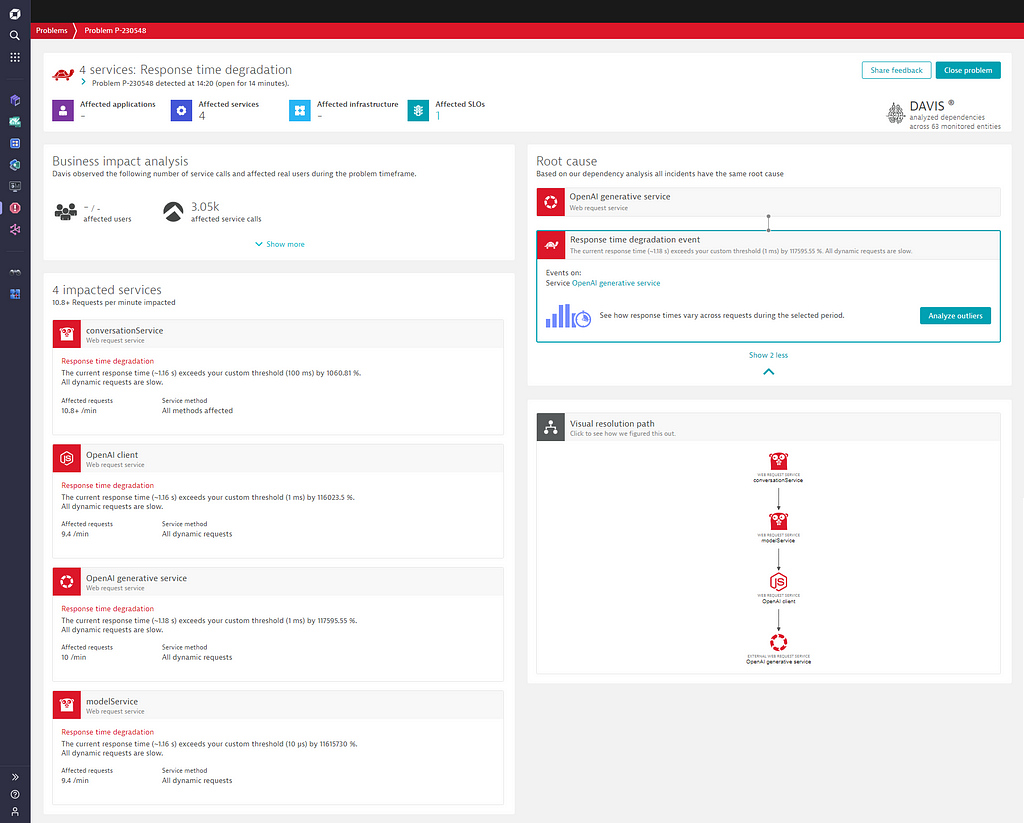
The Davis problem details do show all affected services, OpenAI generative service as root-cause for the slowdown along with the ripple effect of its slowdown.
The problem details also list all Service Level Objectives that were negatively impacted by this slowdown.
Summary
The massive popularity of generative AI cloud services, such as OpenAI’s GPT-4 model, forces companies to rethink and to redesign their existing service landscapes. Integrating generative AI into traditional service landscapes comes with all kinds of uncertainties. Using Dynatrace to observe OpenAI cloud services helps to gain cost transparency and to ensure the operational health of your AI enhanced services.
Full transparency and observability of AI services also play a significant role in upcoming AI regulations at a national level and within risk assessments within your own company.
For further information you can find the full source of the NodeJS service on GitHub.
Dynatrace Davis AI automatically monitors OpenAI ChatGPT for performance, reliability and cost was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.