
A tool to execute them all: the Job Executor Service
A radical new approach to running tasks with Keptn: run any container as a Kubernetes Job orchestrated by Keptn.
By Thomas Schuetz, Dominik Augustin, & Dieter Ladenhauf
In part one of this series, I shared the story of why and how some of our Dynatrace teams are looking into adopting Keptn for our microservice deployment strategy. For a refresher on what’s happened, just click on this link:
How we are redesigning our microservices deployment strategy
The problem with too many frameworks
Now that the deployment is ready, we needed to run tests to ensure that the code works correctly. We agreed on running health, functional, and load tests — and for each typology, we were using a different framework. Keptn already had some existing services for JMeter and Locust, which was great for load testing, but we needed to create new services for other frameworks that we wanted to use, like JUnit, REST Assured, and Testcafe.
You can probably already see the issue we were running into: building new services is easy, but it takes a lot of effort to maintain them. And the more frameworks you add, the higher maintenance costs become.
The services themselves were doing simple tasks:
- Pull the appropriate configuration files from the Keptn configuration service.
- Execute tests with these configurations.
- Send an event back to Keptn with a success or failure state.
So, to solve the maintenance issue and simplify the testing process, we came to a solution and called it the “Job Executor Service” (JES).
How the Job Executor Service works
The JES is a Keptn service with which you can configure Kubernetes Jobs that will be triggered on certain events sent out by Keptn. These Jobs are called Actions in the JES configuration.
Each Action can trigger multiple tasks, but each task is a single Kubernetes job.
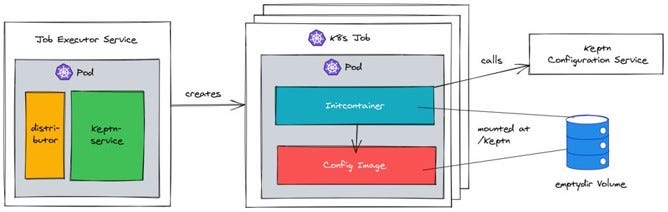
A Kubernetes Job consists of two parts: one Initcontainer and one actual workload Image. The amazing part is you can just use any available workload Image out there. For example, JMeter would have a standard JMeter image; Locust would have a standard Locust image. This greatly reduces the need to create your own images.
The Initcontainer has a special role, it calls the Keptn Configuration Service and grabs the appropriate configuration files needed for this Job. It puts them in an emptyDir Volume that will be mounted in the workload image. They are then available in a directory called /keptn.
What are the advantages of the Job Executor Service?
As previously mentioned, one of the biggest advantages and the reason why we developed the JES, was the reduced maintenance effort. Our teams only need to implement a new Keptn Service functionality once — in the JES, and it is immediately available for all configured Jobs. No more need to implement the same functionality into each service you use.
Furthermore, we also discovered the benefit of reduced resource usage. Jobs are only using resources on the cluster while they are running, and not while they’re idle. After they have completed their task, they are terminated, and new job will be created upon invocation when required.
Use Case: Provisioning infrastructure with Keptn
I’ve described the implementation and how the JES works, so now let’s look at a real-life example: provisioning the infrastructure with Keptn.
Already before adding Keptn to our deployment, we were using Terraform as part of our CI tools to rollout our infrastructure. So, we created a job for the JES to run our Terraform deployment.
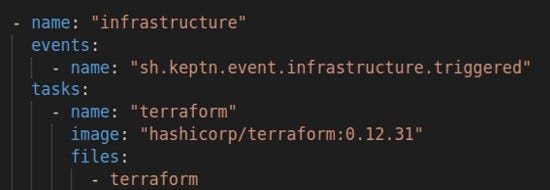
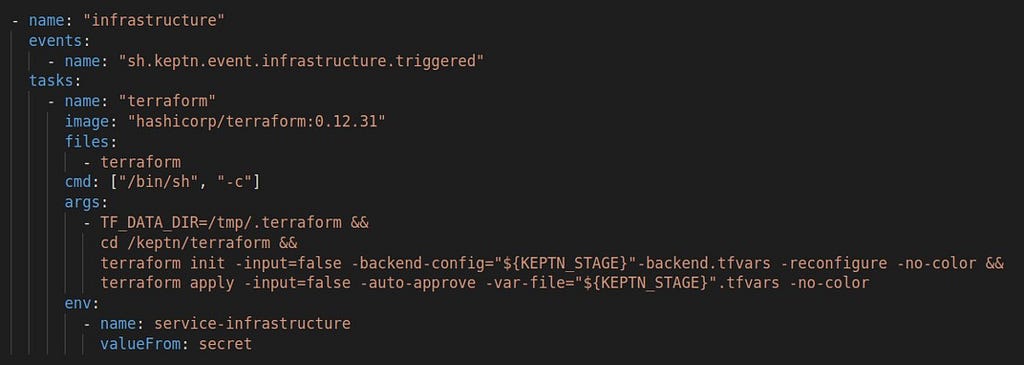
Our first step was to add a task called “infrastructure” in the shipyard configuration. As part of the deployment sequence, Keptn will then send out a sh.keptn.event.infrastructure.triggered, for which we created a new Action (task). We also use the official terraform image (this simplifies things — it already has the image, we don’t need to create one).
name: “infrastructure”
events:
- name: “sh.keptn.event.infrastructure.triggered”
tasks:
- name: “terraform”
image: “hashicorp/terraform: 0.12.31”
In the Keptn configuration repository, the Terraform files will look like in the picture below. We have dev configurations in the dev stage (branch), and we have hardening configurations in the hardening stage (branch).
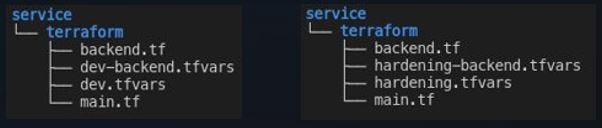
The triggered event sent out by Keptn includes some metadata, including the name of the stage. While the Terraform configuration only specifies that it needs Terraform files, the underlying JES automatically provides the Terraform files specific to this stage. I.e., the event specifies dev, so the JES provides the files for dev. All these files are then available under /keptn.
Moving on, we need to create the job command, which looks a bit complicated at first glance, but is quite simple:
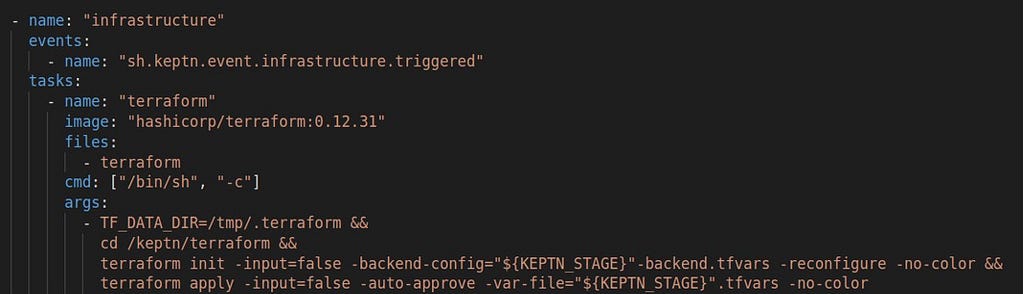
With the job command, we are overwriting the entry point command from the Terraform image with “sh”. This allows us to chain multiple commands together. First, we define with TF_DATA_DIR which directory Terraform should use for storing its downloaded modules, and then we move into the mounted /keptn directory, where configuration files live. Terraform itself requires only two commands: init and apply. The terraform commands also include environment variables, these are prepared by the JES in the background with the information of the incoming Keptn event.
The final step is to provide the credentials Terraform needs. The JES is equipped with a feature that imports Kubernetes secrets. Kubernetes secrets are key-value pairs and the JES provides them as environment variables with the key as the name. We don’t need to do anything special here, since Terraform expects the credentials as environment variables
And that’s it. You can now configure your infrastructure in a way that’s separate from the actual application code. This is a great step in the right direction because it prevents the issue of not having the correct infrastructure in place when the application is s promoted to the next stage by developers.
JES benefits in a nutshell
- Fewer consumed resources. The defined Keptn tasks are run as short-lived Kubernetes jobs, which means that resources are consumed only while the task is executed.
- Less maintenance. This service can execute any framework with just a few lines of YAML configuration. No need to write or maintain new code.
- Trigger task execution for any Keptn events. Keptn services usually filter for a static list of events that trigger the functionality, so the code needs to be changed for every new event. The JSE automates this by matching a JSON path to the received event payload.
- Run any workload orchestrated by Keptn. Support new functionalities of Keptn just once in this service — and all workloads profit from it.
Try it out
The Job Executor Service is currently available in the Keptn-contrib repository on Github.
You can check it out and get more information here: https://github.com/keptn-contrib/job-executor-service
Some final thoughts
To recap, we managed to solve a lot of issues during our journey:
- The deployment stability and the helm service are more stable
- Tests, deployment configurations, and container images of the service fit together, enabling us to constantly promote services
- The possibilities of the Job Executor Service are endless. Just plug and play!
- Developers don’t need to know how Keptn works to use it. We’ve almost completely abstracted it from them.
- Automated CI/CD integration is possible thanks to one shell script pushing the configuration files to Keptn.
This Keptn Internal Adoption project is far from over, but we are happy with what we have achieved until now and we are excited about our further development plans.
A tool to execute them all: the Job Executor Service was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.