
5 Takeaways from talking about performance engineering with Taras Tsugrii from Facebook
The importance of predictable data structures, the cultural impact of fast deployments, how to make developers care about performance, and more.

In one of our latest Pure Performance podcasts, Brian Wilson and I had the pleasure to host Taras Tsugurii, software engineer and one of the best-known performance engineering experts in the field, with experience in some of the biggest tech companies: Facebook, Google, Microsoft.
If you don’t know him already, Taras has been working at Facebook since 2015 and worked in multiple teams with the goal of improving system performance. He’s worked with the compilers, with the build infrastructure, with the CI infrastructure and now he’s working on the release infrastructure. It was great to have him on the podcast and to be able to pick his brain on everything performance engineering.
Here are 5 takeaways from our chat, ranging various topics from data structures to observability, and also from company culture to optimization strategies. Read until the end to find out what our key learning is. 😉
Listen to the talk in full here: Old patterns powering modern tech leading to same old performance problems with Taras Tsugrii
Data predictability is the key to performance optimization
One of the keys to optimizing performance is to figure out how to organize your data. It needs to be done in a predictable way and not in a random way, because it can slow you down.
Just like in your apartment, it’s easy for you to find something you’re looking for if you know where it is located. You don’t have to waste time searching everywhere for your keys — you know they’re in the bowl close to the door. And the same concept applies to data.
One important thing is knowing and understanding the API you are using. All APIs are developed with a certain set of assumptions and if you know those assumptions you can leverage them in the most efficient way. It’s useful to know all the properties of your data in advance. Imagine that you have an array of numbers and you need to check if there is a certain number there. If you do not know that array, you need to use something like a linear scan. But if you know that it’s sorted, you can do a binary search, which is presumably much faster than a linear scan. Just knowing this is extremely useful. You could also use a CPU branch predictor to have better performance. If it’s possible to predict what the next request will be, the pre-fetcher can already fetch the needed data and prepare it for you and cache it. This speeds up the process, instead of having to look through all the data every time a new request comes.
Unfortunately, every situation is unique, so there is no one-advice-fits-all. But there are already many tried and tested techniques like “parallel arrays” — commonly used in game development — that can help you speed up data requests.
Taras covered data layout and fetching strategies intensively in his recent talk at Neotys PAC if you are interested in more details.
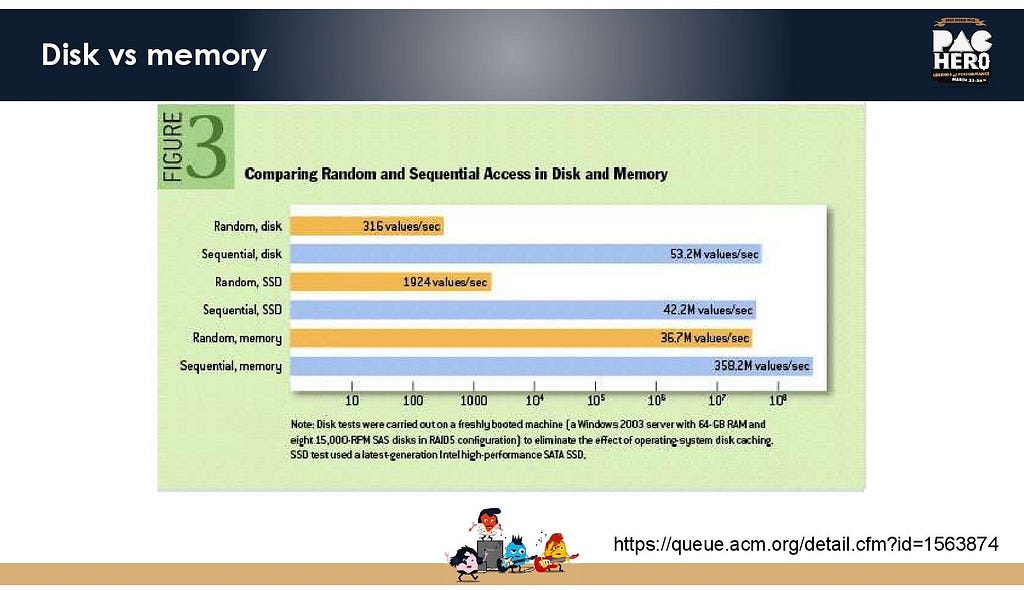
Continuous compiler optimization strategies based on production telemetry
Performance optimizations need to be done based on production data to ensure that they actually bring benefits to the users of your software or system. If you would optimize based on stage test executions, for example, you cannot be sure that the data access patterns used in these tests are accurate to those used in production.
“First you build the binary with the extra instrumentation, then you feed your inputs to that binary, which generates the profile, and then you feed that profile into the next compilation, which generates your final binary.” You cannot know in advance what the best access pattern is, but you can use the last profile that worked and ship it to a small percentage of your users. Then gather data from those users to generate a new profile, then use that profile to generate the final binary to ship to all of your users. Like a continuous feedback loop.
Taras sees the CI/CD pipeline as a circle, and not as an interval from point A to B. The pipeline is a continuous loop where you feed production data into the build phase, which is going to produce the new binary that is itself going to be pushed to production. Lastly, you enable monitoring. That’s why he’s a huge fan of things like Keptn that simplify the construction of this continuous feedback loop.
Use observability data to improve your performance
Observability and monitoring platforms collect huge amounts of useful information, but it often this data is not being leveraged in the correct way to improve things in terms of performance.
The more granular data you have, the better, of course. But even the coarse grain data can be interesting. For example, if you know that one of your methods is pretty slow, then maybe you can allocate a bigger budget for your compiler to spend on that function. Or, thinking even further, imagine being a developer and wanting to use this method, but getting a notification from your IDE saying that this method is slow, thus expensive for your company. This could make you rethink your code and maybe find a better way to do it, without affecting performance and increasing costs.
“I’m a huge fan of the observability space but I believe we need to close the gap between the vast amount of data we get from it, and how we use it. We don’t take advantage of all the data we gather, it’s a shame.”
Speak the developer’s language to make them care about performance
Knowing what to do to improve performance is not enough — you also need to find people who support you in implementing the needed changes. And that begs the question: “How do you make developers care about performance?”
According to Taras, it’s important that developers understand what the impact is going to be. Instead of talking about milliseconds or allocations, use specific terminology that can be understood. It makes a difference whether you say: “the page will load 100 milliseconds slower and that will decrease our revenue of 2%” or whether you say: “the page will load 1 second slower and that will make us lose 2 million dollars in revenue” (numbers used only as examples).
Key learning: Build performance impacts development and deployment behavior
Taras believes that company culture is impacted by the system infrastructure, just like Conway’s law states that organizational structures are reflected in the system’s architecture.
For example, if your infrastructure only allows for slow builds, then it is likely that you are not incentivized to build often. Consequently, you will make bigger deployments with more time in-between, which are hard to test, and then you’ll have low test coverage. TDD is not particularly suitable for slow builds.
This also de-incentivizes people from doing refactoring and this particularly affects performance work. If you need to wait hours to see if your changes have worked, you are less likely to want to do it — meaning, you are less likely to want to explore the code and experiment.
Infrastructural restrictions influence directly how your developers work:
“If you have fast builds, it’s more likely that your company is Agile and that your developers can be more experimental and not be afraid to fail.”
In conclusion
I could have continued talking to Taras for hours about performance engineering, but unfortunately, we have to limit our Pure Performance episodes to one hour (nobody wants to listen to somebody talk for longer 😉). I hope that we can welcome Taras again on the podcast soon enough, but in the meantime, I’d like to thank him again for his valuable input and for coming on the show.
If you’d like to, listen to the full podcast here: Old patterns powering modern tech leading to same old performance problems with Taras Tsugrii. Or I can also highly recommend watching Taras’ talk at NeotysPAC on Old Patterns Powering Modern Tech.
5 Takeaways from talking about performance engineering with Taras Tsugrii from Facebook was originally published in Dynatrace Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.